
Najważniejsze elementy ochrony chmury to tożsamość, konfiguracja, logi i odzyskiwanie danych
- MFA, segmentacja uprawnień i porządek w kontach administracyjnych zwykle dają szybszy efekt niż zakup kolejnej usługi.
- Najczęstsze incydenty biorą się z błędnych konfiguracji, nadmiernych uprawnień, niechronionych API i wyciekających sekretów.
- Linux w chmurze wymaga twardych podstaw: kluczy SSH, minimalnych obrazów, automatycznych poprawek i audytu.
- RODO i umowy trzeba uwzględnić zanim dane trafią do regionu lub usługi zarządzanej.
- Backup ma sens tylko wtedy, gdy potrafisz go odtworzyć w praktyce.
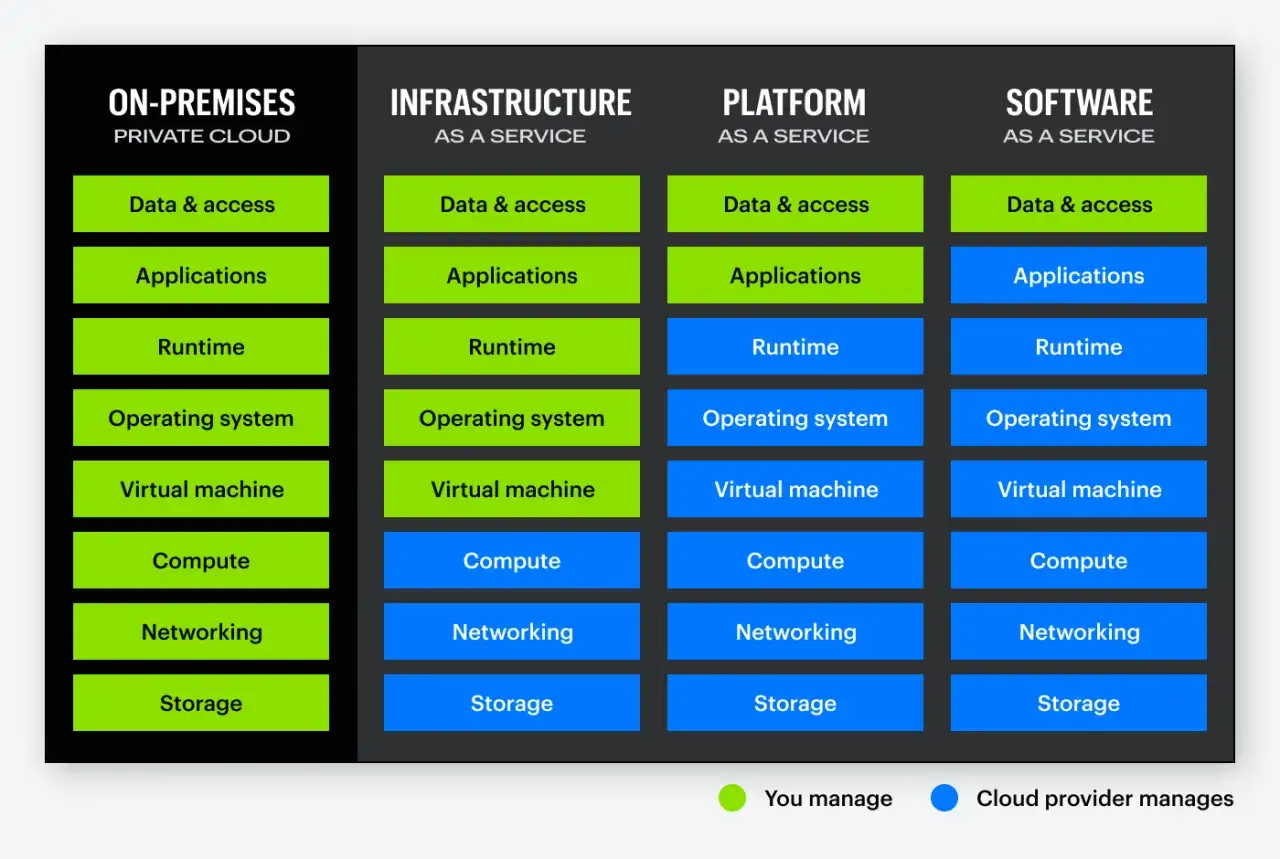
Gdzie kończy się odpowiedzialność dostawcy, a zaczyna twoja
Pierwszy błąd, który widzę najczęściej, to założenie, że po przeniesieniu systemu do chmury dostawca „bierze na siebie bezpieczeństwo”. W rzeczywistości odpowiedzialność jest współdzielona i zależy od modelu usługi: im bliżej IaaS, tym więcej kontroli, ale też więcej pracy po twojej stronie. Im bliżej SaaS, tym mniej patchowania, lecz wciąż zostają tożsamość, dane, konfiguracja uprawnień i polityki dostępu.
| Obszar | IaaS | PaaS | SaaS |
|---|---|---|---|
| Fizyczna infrastruktura | dostawca | dostawca | dostawca |
| System operacyjny i poprawki | klient | dostawca | dostawca |
| Aplikacja i jej konfiguracja | klient | wspólnie | dostawca |
| Tożsamość, role i uprawnienia | klient | klient | klient |
| Dane, klasyfikacja i klucze | klient | klient | klient |
| Monitoring i reagowanie na zdarzenia | wspólnie | wspólnie | klient |
Jeśli nie masz tego modelu rozpisanego na kartce, łatwo przeoczyć miejsce, w którym luka faktycznie powstaje. Gdy zespół ma jasny podział odpowiedzialności, dużo prościej przejść do modelu Zero Trust, czyli podejścia, w którym każde żądanie dostępu trzeba potwierdzić, a nie zakłada się z góry, że „ktoś już jest zaufany”.
Właśnie na tym tle najlepiej widać, skąd biorą się problemy, które dziś kosztują firmy najwięcej. Zwykle nie są efektowne, ale są powtarzalne i przewidywalne.
Najczęstsze luki, które otwierają drogę do incydentu
W najnowszym obrazie zagrożeń ENISA widać 4875 incydentów z okresu od 1 lipca 2024 do 30 czerwca 2025, a na czele nadal stoją ataki na dostępność i ransomware. W chmurze oznacza to jedno: przeciwnik nie musi łamać wszystkiego od zera, jeśli wcześniej trafi na błędną konfigurację albo przejęte konto.
- Błędna konfiguracja to publicznie dostępny bucket, zbyt szeroki security group albo panel administracyjny wystawiony bez potrzeby do internetu. To nadal jedna z najprostszych dróg do wycieku.
- Nadmierne uprawnienia w IAM, czyli zarządzaniu tożsamością i dostępem, są groźniejsze niż się wydaje. Jedno konto z prawami „na wszelki wypadek” potrafi otworzyć cały katalog usług.
- Sekrety w kodzie i CI to klucze API, tokeny i hasła, które trafiają do repozytoriów, logów budowania albo zmiennych środowiskowych bez kontroli rotacji.
- Niechronione API oznacza brak limitów, brak walidacji i brak sensownej autoryzacji. W praktyce łatwo wtedy o nadużycie, a trudno o szybkie wykrycie.
- Brak obserwowalności nie jest tylko brakiem logów. To także brak korelacji zdarzeń, alertów i możliwości odtworzenia, co się stało w pierwszych minutach incydentu.
- Kopie zapasowe w tej samej domenie zaufania bywają bezużyteczne, jeśli napastnik po przejęciu konta może skasować także snapshoty i archiwa.
- Łańcuch dostaw obejmuje obrazy kontenerów, biblioteki, moduły IaC i gotowe komponenty z marketplace. W chmurze zaufanie do cudzych paczek trzeba budować tak samo ostrożnie jak do własnego kodu.
Najbardziej kosztowne są błędy, które wyglądają jak drobna pomyłka administracyjna. Z tego powodu następny krok nie powinien polegać na kupowaniu wszystkiego naraz, tylko na ustawieniu sensownej kolejności działań.
Co wdrożyć najpierw, gdy nie da się zrobić wszystkiego naraz
Gdy pracuję z zespołem, nie zaczynam od „idealnej architektury”. Zaczynam od kilku punktów kontrolnych, które najszybciej zmniejszają ryzyko przejęcia konta albo utraty danych. NIST w 2025 pokazał 19 przykładowych implementacji Zero Trust dla środowisk rozproszonych i wielochmurowych, ale w praktyce i tak najwięcej dają podstawy, a nie efektowne dodatki.
| Priorytet | Co robię | Dlaczego to działa |
|---|---|---|
| 1. Tożsamość | Włączam MFA dla wszystkich kont administracyjnych i dostępu zdalnego, a dla adminów stosuję klucze sprzętowe. | Przejęte hasło przestaje wystarczać. |
| 2. Uprawnienia | Wdrażam zasadę najmniejszych uprawnień i dostęp JIT, czyli nadawany tylko na krótki czas do konkretnego zadania. | Ograniczam skutki błędu i skracam okno ataku. |
| 3. Logowanie | Zbieram logi do centralnego miejsca i ustawiam alerty na logowania, eskalacje uprawnień oraz zmiany konfiguracji. | Szybciej widzę nietypowe zachowanie. |
| 4. Sekrety | Przenoszę hasła, tokeny i klucze do menedżera sekretów, a potem ustawiam rotację i kontrolę dostępu. | Zmniejszam ryzyko wycieku z kodu, repozytorium i pipeline'u. |
| 5. Szyfrowanie | Szyfruję dane w spoczynku i w transmisji, a klucze trzymam w KMS, czyli usłudze do zarządzania kluczami kryptograficznymi. | Przechwycone dane są trudniejsze do użycia. |
| 6. Kopie i odzyskiwanie | Trzymam kopie w modelu 3-2-1 i regularnie testuję odtworzenie. | Backup przestaje być tylko deklaracją na papierze. |
| 7. Kontrola konfiguracji | Używam CSPM, czyli narzędzia do stałej oceny konfiguracji chmury, oraz polityk jako kodu. | Wykrywam odchylenia zanim zamienią się w incydent. |
Jeśli budżet i czas są naprawdę ograniczone, zaczynam od pierwszych trzech pozycji. Reszta ma sens dopiero wtedy, gdy podstawowy porządek w dostępie i logach już istnieje. W środowiskach opartych na Linuksie ten sam zestaw zasad trzeba potem przełożyć na serwery, kontenery i pipeline'y, bo tam błędy rozchodzą się wyjątkowo szybko.
Jak zabezpieczyć linuksowe serwery, kontenery i pipeline'y
W ekosystemie linuksowym chmura daje dużą elastyczność, ale nie zwalnia z twardego hardeningu. Najwięcej problemów widzę tam, gdzie zespół zakłada, że obraz systemu, kontener albo pipeline są „tymczasowe” i przez to mniej ważne niż klasyczny serwer.
Na serwerach
- Logowanie hasłem przez SSH wyłączam, jeśli tylko mogę, i zostawiam klucze z ograniczeniami po stronie źródła.
- Pakiety i usługi ograniczam do minimum. Im mniej na maszynie, tym mniejsza powierzchnia ataku.
- Aktualizacje bezpieczeństwa mają mieć jasny rytm albo automatyzację, a nie być „na kiedyś”.
- Audyt obejmuje sudo, zmiany w konfiguracji i logowania administracyjne.
- Fail2ban bywa pomocny, ale nie zastąpi MFA i porządnego dostępu sieciowego.
- Live patching ma sens w systemach krytycznych, ale nie powinno być wymówką do odkładania normalnych restartów i pełnych aktualizacji.
W kontenerach
- Uruchamianie bez roota oraz ograniczenie capabilities znacząco zmniejszają skutki kompromitacji.
- Obraz bazowy powinien być minimalny i przypięty do wersji albo digestu, nie do „latest”.
- System plików warto montować tylko do odczytu tam, gdzie to możliwe.
- Sekrety trzymam w menedżerze sekretów, a nie w zmiennych środowiskowych czy plikach repozytorium.
- Skanowanie obrazów i polityki wejścia do rejestru powinny blokować znane podatności jeszcze przed wdrożeniem.
Przeczytaj również: Ochrona przed malware - Czy Twoje urządzenie jest bezpieczne?
W CI/CD
- Runnery efemeryczne są bezpieczniejsze niż stałe, bo nie kumulują śmieci konfiguracyjnych i sekretów.
- Podpisywanie artefaktów pomaga odróżnić build zaufany od podmienionego.
- Kontrola gałęzi, recenzje i skanowanie IaC, czyli infrastruktury opisanej kodem, ograniczają błędy, które w chmurze rozchodzą się bardzo szybko.
- Uprawnienia pipeline'u powinny być mniejsze niż uprawnienia człowieka, który go utrzymuje.
W praktyce właśnie tutaj wychodzą na jaw różnice między zespołem, który naprawdę panuje nad środowiskiem, a tym, który tylko liczy, że platforma chmurowa wszystko załatwi. Kolejny poziom to już nie technika sama w sobie, ale zgodność z wymaganiami firmy i przepisami, zwłaszcza gdy w grę wchodzą dane osobowe.
Jak pogodzić chmurę z rodo i wymogami polskiej firmy
W polskich firmach temat chmury prawie zawsze kończy się na dwóch pytaniach: gdzie są dane i kto ma do nich dostęp. Jeśli w grę wchodzą dane osobowe, dokumenty kadrowe, materiały finansowe albo logi z identyfikatorami użytkowników, techniczna wygoda musi iść w parze z porządkiem prawnym i organizacyjnym.
- Klasyfikuję dane przed migracją. Inaczej traktuję publiczne treści, inaczej dane klientów, a jeszcze inaczej dane wrażliwe albo objęte tajemnicą firmową.
- Sprawdzam region przetwarzania, kopie zapasowe i mechanizmy failover. Sam wybór regionu w UE nie kończy tematu, jeśli backupy lub logi lądują gdzie indziej.
- Porządkuję umowy, w tym powierzenie przetwarzania i listę podwykonawców. Bez tego łatwo zgubić odpowiedzialność, gdy usługi są rozproszone.
- Weryfikuję transfer poza EOG, jeśli w ogóle zachodzi. W praktyce trzeba sprawdzić podstawę prawną, politykę dostawcy i sposób zabezpieczenia dostępu administracyjnego.
- Ustalam retencję i kasowanie. Kopia zapasowa nie może żyć własnym życiem dłużej niż dane produkcyjne, jeśli polityka firmy tego nie przewiduje.
- Przygotowuję procedurę incydentu. Kto wykrywa, kto ocenia, kto zgłasza i kto odzyskuje usługi to pytania, które trzeba zamknąć przed awarią, nie po niej.
Najlepiej działa prosta zasada: najpierw klasyfikacja danych, potem wybór regionu i dopiero na końcu konkretny zestaw usług. Dzięki temu decyzja nie jest tylko techniczna, ale też organizacyjna i zgodna z tym, jak firma naprawdę działa.
Jak porównywać modele i dostawców bez marketingowego szumu
Najwięcej błędów zakupowych widzę wtedy, gdy zespół porównuje tylko cenę vCPU albo gigabajtów. Z perspektywy bezpieczeństwa ważniejsze są zakres odpowiedzialności, jakość logów, możliwość egzekwowania polityk, odzyskiwanie danych i to, jak łatwo przenieść usługę do innego środowiska.
| Model | Kiedy ma sens | Plusy | Ograniczenia |
|---|---|---|---|
| Public cloud | Gdy liczy się szybkie wdrożenie, skalowanie i dostęp do usług zarządzanych. | Mało bariery wejścia, dużo automatyzacji, szybkie odtwarzanie środowisk. | Więcej zależy od konfiguracji i jakości IAM po stronie klienta. |
| Private cloud | Gdy organizacja chce większej kontroli nad środowiskiem i ma własny zespół operacyjny. | Większa przewidywalność i możliwość dopasowania polityk. | Droższa i trudniejsza w utrzymaniu, a błędy operacyjne zostają po twojej stronie. |
| Hybrid cloud | Gdy część usług musi zostać lokalnie, a część może działać elastycznie w chmurze publicznej. | Dobry kompromis dla systemów o różnym poziomie wrażliwości. | Największa złożoność integracji, tożsamości i monitoringu. |
Nie istnieje model „najbezpieczniejszy” w oderwaniu od ludzi i procesu. Czasem SaaS jest bezpieczniejszy operacyjnie niż własny IaaS, bo zmniejsza ryzyko błędów administracyjnych, ale zabiera część widoczności. Czasem private cloud daje spokój regulacyjny, ale kosztuje więcej niż zespół jest w stanie utrzymać bez skrótów.
Dlatego podczas oceny dostawcy patrzę jeszcze na kilka rzeczy: czy logi da się łatwo eksportować, czy SSO i MFA integrują się bez obejść, czy są opcje kluczy zarządzanych przez klienta, czy backup jest odporny na kasowanie z głównego konta, i czy odzyskanie danych nie wymaga ręcznego proszenia supportu o każdą drobną rzecz. Jeśli te odpowiedzi są mgliste, marketing nie powinien przesłaniać ryzyka.
Po takim porównaniu warto przejść z teorii do krótkiego planu wdrożenia, bo to właśnie on pokazuje, czy środowisko jest naprawdę pod kontrolą.
Plan na 30 dni, który realnie podnosi poziom ochrony
- Tydzień 1 - robię inwentaryzację zasobów, klasyfikuję dane, wskazuję właścicieli systemów i usuwam nieużywane konta oraz stare klucze dostępu.
- Tydzień 2 - włączam MFA wszędzie, gdzie to możliwe, porządkuję role, odcinam nadmiarowe uprawnienia i rozdzielam środowiska produkcyjne od testowych.
- Tydzień 3 - centralizuję logi, ustawiam alerty, przenoszę sekrety do właściwego magazynu i sprawdzam politykę rotacji kluczy.
- Tydzień 4 - wykonuję test odzyskania, skanuję IaC i obrazy, sprawdzam procedurę incydentu oraz zapisuję, co dokładnie trzeba poprawić w kolejnym miesiącu.
Jeśli miałbym zostawić jedną praktyczną zasadę, byłaby prosta: dobre bezpieczeństwo w chmurze zaczyna się od widoczności, kontroli tożsamości i sprawdzonego odzyskiwania danych. Gdy te trzy elementy działają, reszta przestaje być chaosem, a staje się normalną, przewidywalną eksploatacją.