
Skuteczna ochrona przed ransomware nie zaczyna się od jednego programu, tylko od kilku warstw: kopii zapasowych, ograniczenia uprawnień, aktualizacji i szybkiej reakcji. W praktyce chodzi o to, żeby atakujący nie miał łatwego wejścia, nie mógł się swobodnie poruszać po sieci i nie mógł zniszczyć danych, z których później trzeba wracać do pracy. Poniżej pokazuję, które elementy naprawdę robią różnicę, gdzie najczęściej popełnia się błędy i jak podejść do tematu na serwerach z Linuxem.
Najkrótsza droga do odporności na ransomware
- Najczęstsze wejścia to phishing, skradzione loginy, wystawione usługi zdalne i niezałatane luki.
- Backup offline albo niezmienialny jest ważniejszy niż każdy pojedynczy „antywirusowy” gadżet.
- MFA, najmniejsze uprawnienia i segmentacja ograniczają ruch boczny i skalę szkód.
- Aktualizacje publicznych usług i zamykanie zbędnych portów często dają szybszy efekt niż rozbudowa stosu narzędzi.
- Na Linuksie warto włączyć SSH z kluczami, oddzielne konta administracyjne, kontrolę dostępu i kopie poza hostem.
Gdzie atak zaczyna się najczęściej
Ransomware rzadko pojawia się znikąd. Zwykle zaczyna się od jednego błędu: kliknięcia w zły załącznik, użycia wycieku hasła, zostawienia na internet wystawionego panelu albo opóźnienia poprawek na serwerze, który „jeszcze działa”. Jak pokazują komunikaty CERT Polska, phishing nadal jest jednym z najprostszych sposobów wejścia do środowiska, a potem napastnik próbuje przejąć kolejne konta i usługi.
- Phishing i fałszywe logowania - kradzież hasła albo tokenu daje często więcej niż sam malware.
- Wystawione usługi zdalne - VPN, SSH, RDP i panele administracyjne bez dodatkowych barier są częstym celem.
- Podatne aplikacje webowe - stary CMS, panel CMS, backup panel czy wtyczka z luką potrafią otworzyć drogę do całej sieci.
- Łańcuch dostaw - integrator, dostawca oprogramowania albo skrypt administracyjny z nadmiernymi uprawnieniami.
Wniosek jest prosty: nie wystarczy pilnować jednego punktu wejścia. Trzeba zidentyfikować wszystkie miejsca, w których ktoś może się uwierzytelnić, uruchomić kod albo przejść dalej. To prowadzi wprost do kwestii kopii zapasowych, bo one decydują o tym, czy incydent kończy się przestojem, czy katastrofą.
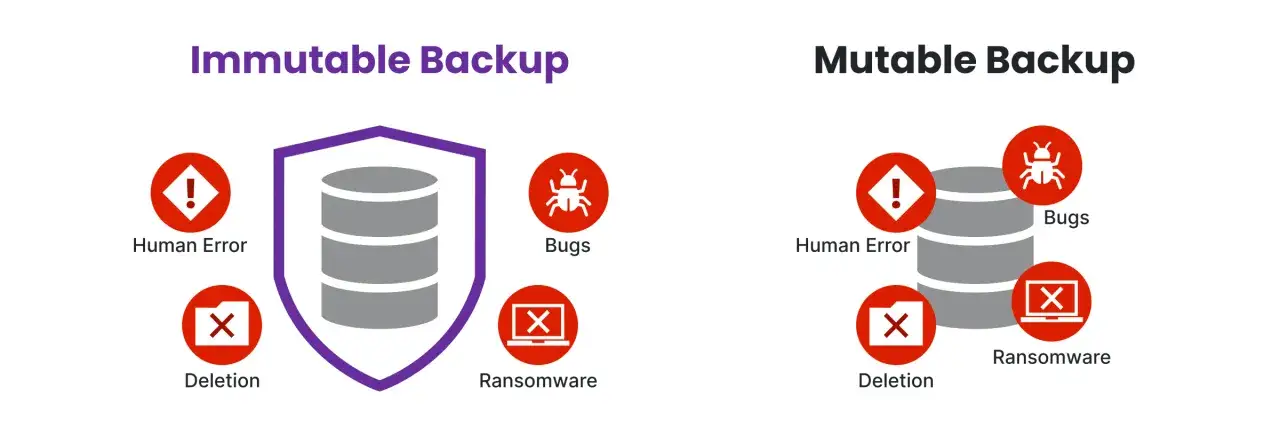
Dlaczego kopia zapasowa jest ważniejsza niż sam antywirus
Ja zaczynam od backupu, bo to jedyny element, który naprawdę pozwala wrócić do działania bez negocjacji z napastnikiem. CISA zaleca utrzymywanie offline, zaszyfrowanych kopii zapasowych i regularne testowanie odtwarzania, ponieważ ransomware bardzo często próbuje zaszyfrować albo usunąć także dane służące do odzyskania środowiska.
| Wariant kopii | Co daje | Główne ryzyko | Kiedy ma sens |
|---|---|---|---|
| Backup na tym samym serwerze lub NAS | Szybki dostęp i prosty restore | Atakujący może go zaszyfrować razem z produkcją | Tylko jako kopia robocza, nie jako jedyna linia obrony |
| Kopia offline lub odłączana | Jest trudna do naruszenia zdalnie | Wymaga dyscypliny przy rotacji i testach | Dobry wybór dla mniejszych i średnich środowisk |
| Kopia niezmienialna, WORM lub object lock | Chroni przed nadpisaniem i kasowaniem | Trzeba dobrze ustawić retencję i uprawnienia | Gdy zależy Ci na odporności na sabotaż i błędy administracyjne |
WORM, czyli write once, read many, oznacza zapis, którego nie da się po prostu nadpisać. To nie jest cudowny pancerz, ale w praktyce bardzo utrudnia atakującemu zniszczenie ostatniej kopii.
- Stosuj zasadę 3-2-1 - trzy kopie danych, na dwóch różnych nośnikach, z jedną kopią poza główną infrastrukturą.
- Szyfruj kopie i trzymaj osobne uprawnienia do systemu backupowego.
- Testuj odtwarzanie po większych zmianach i cyklicznie w scenariuszu awaryjnym.
- Chroń backup tak samo jak produkcję - osobne konta, brak współdzielonych haseł, ograniczony dostęp sieciowy.
Jeśli backup jest tylko „gdzieś zapisany”, to w praktyce nie masz backupu, tylko nadzieję. Kolejny krok to ograniczenie tego, co napastnik może zrobić po zdobyciu pierwszego konta.
Jak ograniczyć zasięg ataku przez MFA, uprawnienia i segmentację
W wielu incydentach prawdziwy problem nie leży w samym wejściu, tylko w tym, że po wejściu atakujący może poruszać się dalej bez większych przeszkód. Dlatego traktuję MFA, najmniejsze uprawnienia i segmentację sieci jako jeden zestaw, a nie trzy oddzielne dodatki.
- MFA wszędzie tam, gdzie ma znaczenie - poczta, VPN, panele administracyjne, chmura, SSH z jump hosta i systemy backupowe.
- Oddzielne konto administracyjne - codzienna praca na zwykłym koncie, administracja tylko wtedy, gdy jest potrzebna.
- Brak kont współdzielonych - jedno konto = jeden właściciel = jeden ślad audytowy.
- Segmentacja - produkcja, backup, stacje robocze i administracja powinny być rozdzielone przynajmniej logicznie.
- Ograniczenie ruchu bocznego - jeśli jedna maszyna padnie, reszta nie powinna być dostępna „z marszu”.
Najczęstszy błąd, który widzę, to włączenie MFA tylko dla części systemów. To poprawa, ale połowiczna. Jeśli poczta jest zabezpieczona, a panel backupu już nie, napastnik nadal ma drogę do szyfracji i sabotażu. Po uporządkowaniu tożsamości trzeba jeszcze zamknąć najtańsze wejścia, czyli stare usługi i zalegające poprawki.
Aktualizacje i twarde ustawienia, które zamykają najtańsze wektory wejścia
Ransomware lubi środowiska, w których „jeszcze działa” znaczy „zostawmy to na później”. Ja rozdzielam poprawki na trzy koszyki: krytyczne dla usług wystawionych do internetu, ważne dla stacji roboczych i planowe dla systemów odciętych od sieci. Najpierw łata się to, co napastnik może wykorzystać z zewnątrz.
- Najpierw systemy publiczne - VPN, reverse proxy, panele admin, aplikacje webowe, bramy i systemy zdalnego dostępu.
- Usuń zbędne usługi - każdy nieużywany demon, port lub protokół to dodatkowy punkt wejścia.
- Ogranicz makra i podejrzane załączniki - szczególnie tam, gdzie użytkownicy pracują na plikach od zewnętrznych kontrahentów.
- Włącz sensowne logowanie - jeśli nie widzisz prób logowania i anomalii, reagujesz za późno.
- Ogranicz administrację z sieci ogólnej - dostęp do zarządzania tylko z wybranych adresów lub przez osobny kanał administracyjny.
To nie są spektakularne zmiany, ale właśnie one robią dużą różnicę w praktyce. Napastnik częściej korzysta z zaniedbania niż z „superzaawansowanej” techniki. Na Linuksie widać to równie dobrze jak w środowiskach Windows.
Co zmienia podejście na serwerach i stacjach z Linuxem
Linux nie daje immunitetu. Daje natomiast dobre narzędzia, jeśli użyjesz ich konsekwentnie: SSH z kluczami zamiast haseł, osobne konta administracyjne, ograniczenie usług, kontrolę dostępu i kopie poza hostem. W praktyce właśnie te elementy najczęściej decydują, czy incydent zatrzyma się na jednym serwerze, czy obejmie większą część infrastruktury.
- Wyłącz logowanie root po SSH i tam, gdzie to możliwe, wyłącz logowanie hasłem.
- Używaj kluczy i osobnych kont - zwykły użytkownik do pracy, konto uprzywilejowane tylko do administracji.
- Włącz SELinux lub AppArmor - to mechanizmy, które ograniczają, co proces może zrobić nawet po kompromitacji.
- Trzymaj backup poza hostem - nie w katalogu montowanym stale na tym samym serwerze, który ma chronić dane.
- Rozważ snapshoty - ZFS, btrfs albo LVM mogą bardzo pomóc, ale tylko wtedy, gdy snapshot nie jest jedyną kopią i da się go odtworzyć poza bieżącym hostem.
- Aktualizuj bezpieczeństwo systemu i pakietów regularnie, zamiast odkładać poprawki „na okno serwisowe”, które wiecznie się przesuwa.
Na Linuksie szczególnie lubię podejście warstwowe: nawet jeśli jeden mechanizm zawiedzie, drugi ma jeszcze szansę zatrzymać atak albo ograniczyć jego skutki. Gdy mimo tego dojdzie do szyfrowania, liczy się już nie profilaktyka, tylko kolejność reakcji.
Co zrobić, gdy infekcja już się pojawi
Jeśli szyfrowanie już trwa, pierwsza zasada jest prosta: izoluj, a nie eksperymentuj. Najpierw odetnij zainfekowane hosty od sieci i udziałów, potem ustal zakres incydentu, a dopiero później podejmuj decyzję o odzyskiwaniu.
- Odłącz zainfekowane systemy od sieci i wszelkich udziałów współdzielonych.
- Zachowaj logi i próbki - nie czyść wszystkiego natychmiast, bo możesz stracić dane potrzebne do analizy.
- Sprawdź konta i klucze - po opanowaniu sytuacji zmień hasła, tokeny i klucze, których mógł dotknąć incydent.
- Odtwarzaj z czystych kopii - nie z katalogu, który mógł zostać naruszony razem z produkcją.
- Nie zakładaj, że płatność cokolwiek gwarantuje - nawet jeśli w grę wchodzi odzyskanie danych, nie rozwiązuje to problemu kompromitacji i możliwego wycieku.
W praktyce dobrze przygotowany plan reakcji jest równie ważny jak zabezpieczenia prewencyjne. Jeśli nie wiesz, co robić w pierwszych minutach, chaos robi za atakującego połowę pracy.
Od czego zacząć, jeśli chcesz realnie obniżyć ryzyko w tym tygodniu
Gdybym miał wskazać tylko kilka działań o najwyższym zwrocie z wysiłku, ustawiłbym je w takiej kolejności:
- Zabezpiecz backupy - odłącz je od produkcji lub przejdź na kopię niezmienialną i przetestuj odtworzenie.
- Włącz MFA na poczcie, VPN, panelach administracyjnych i systemach backupowych.
- Załatw publiczne usługi - patchuj wszystko, co jest wystawione do internetu, zanim zajmiesz się resztą.
- Rozdziel konta administracyjne od zwykłej pracy i usuń konta współdzielone.
- Przejrzyj SSH, VPN i logowanie - wyłącz hasła tam, gdzie możesz, i upewnij się, że widzisz próby nadużyć.
Jeśli zrobisz tylko te pięć rzeczy porządnie, ryzyko spada bardziej niż po dokupieniu kolejnego narzędzia, które „coś wykrywa”, ale nie pomoże, gdy trzeba odtworzyć system po ataku. Największą różnicę robi nie pojedynczy produkt, tylko zestaw prostych, konsekwentnych warstw: backup, tożsamość, aktualizacje i kontrola dostępu.